Hive中SQL转化为MapReduce的原理
目录
JOIN操作实现原理
在MapReduce中实现join主要有以下几种方式:Reduce-side join、Map-side join、和Repartition join。下面详细介绍这些方法及其原理。
Reduce-side Join
Reduce-side join是MapReduce中最通用的join类型,适用于大规模数据集的连接,特别是当两个数据集都很大且没有任何特殊排序或分区时。
工作原理:
-
Map阶段:
- Mapper读取两个数据集的所有输入数据(可能来自HDFS的不同文件或目录)。
- 对每个输入记录,Mapper输出key-value对,其中key是join操作的键,value是包含数据集标识(如标记来自哪个数据集)和数据记录的值。
-
Shuffle阶段:
- MapReduce框架将所有Mapper输出的key-value对根据key进行分组和排序,然后分发给Reducers。
-
Reduce阶段:
- 每个Reducer接收到特定key的所有记录,这些记录来源于所有的Mapper。Reducer通过检查每条记录的来源数据集标识,将来自不同数据集的记录进行组合。
- 对于每个key,Reducer执行实际的join逻辑(如inner join, left join等),输出最终的结果。
Map-side Join
Map-side join通常在其中一个数据集很小(足够小到可以被加载到内存中)时使用,这种方法效率更高,因为它避免了在Reduce阶段进行大量的数据排序和分组。
工作原理:
-
预处理阶段:
- 小的数据集被分发到所有的Mapper节点上,通常通过将其存储在HDFS上并通过DistributedCache机制让每个Mapper节点访问。
-
Map阶段:
- 每个Mapper读取大的数据集,并同时加载小的数据集到内存。
- Mapper对大数据集的每条记录进行处理,使用内存中的小数据集进行即时join操作。
- 输出join后的结果。
Repartition Join
Repartition join是另一种Reduce-side join的形式,适用于需要特殊排序或分区的场景。
工作原理:
- 类似于普通的Reduce-side join,但在map阶段会对数据进行额外的分区和排序处理,以优化join的效率。
应用场景
- 当两个大数据集需要被连接时,使用Reduce-side join。
- 当一个小数据集可以全局广播到所有Mapper时,使用Map-side join。
- 当数据需要特殊处理或优化分区时,考虑使用Repartition join。
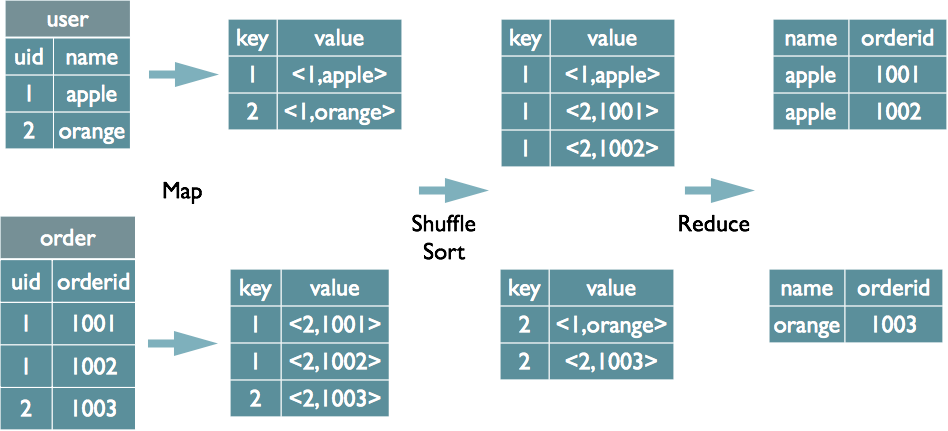
例如一个Reduce-side Join:
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。
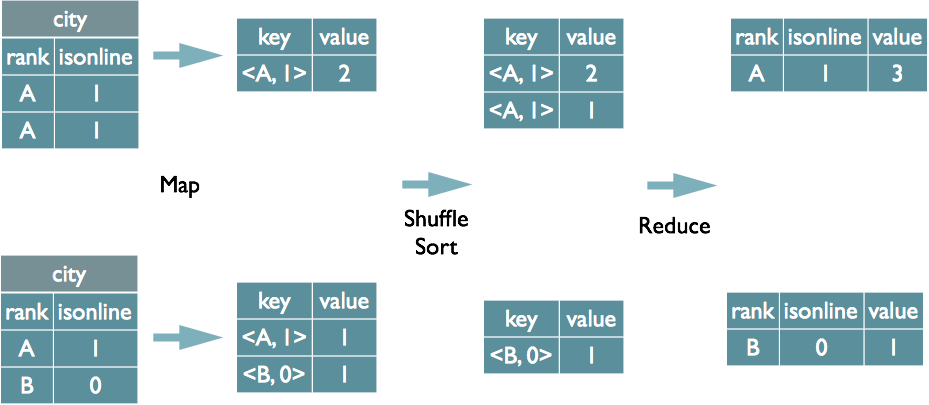
Group By操作实现原理
Map阶段
- 任务:读取输入数据,处理记录,并输出键值对。
- 输出:键是
GROUP BY字段,值是需要聚合的数据。
Shuffle阶段
- 处理:框架自动对Mapper的输出进行排序和分组,确保相同的键被送到同一个Reducer。
Reduce阶段
- 聚合:Reducer接收到键和对应的值集合,进行数据聚合(如计数、求和)。
- 结果:输出每个组基于
GROUP BY字段的聚合结果。
将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。MapReduce的过程如下
SQL转化为MapReduce的过程
整个编译过程分为六个阶段:
-
Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
-
遍历AST Tree,抽象出查询的基本组成单元QueryBlock
-
遍历QueryBlock,翻译为执行操作树OperatorTree
-
逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
-
遍历OperatorTree,翻译为MapReduce任务
-
物理层优化器进行MapReduce任务的变换,生成最终的执行计划
参考文章: