How Hive Translates SQL into MapReduce
How JOIN Operations Are Implemented in MapReduce
MapReduce supports several join strategies: Reduce-side Join, Map-side Join, and Repartition Join. Each is described in detail below.
Reduce-side Join
Reduce-side join is the most general join type in MapReduce. It is well-suited for joining large datasets, particularly when both datasets are large and have no special sorting or partitioning.
How it works:
-
Map phase:
- Mappers read all input data from both datasets (possibly from different HDFS files or directories).
- For each input record, the Mapper emits a key-value pair where the key is the join key and the value contains a dataset tag (indicating which dataset the record came from) along with the record itself.
-
Shuffle phase:
- The MapReduce framework sorts and groups all Mapper output key-value pairs by key, then routes them to the appropriate Reducers.
-
Reduce phase:
- Each Reducer receives all records for a given key from all Mappers. It inspects the dataset tag on each record to distinguish the two data sources and combines them.
- For each key, the Reducer executes the join logic (e.g., inner join, left join) and outputs the final result.
Map-side Join
Map-side join is typically used when one of the datasets is small enough to fit in memory. This approach is more efficient because it eliminates the large-scale sorting and grouping that occurs in the Reduce phase.
How it works:
-
Pre-processing phase:
- The small dataset is distributed to all Mapper nodes, typically by storing it on HDFS and making it accessible to each Mapper via the DistributedCache mechanism.
-
Map phase:
- Each Mapper reads the large dataset and simultaneously loads the small dataset into memory.
- For each record in the large dataset, the Mapper performs an in-memory join against the small dataset.
- The joined result is emitted directly.
Repartition Join
Repartition join is a variant of Reduce-side join that applies additional partitioning and sorting during the Map phase to optimize join efficiency.
How it works:
Similar to a standard Reduce-side join, but with extra partitioning and sorting applied in the Map phase.
When to Use Each
- Use Reduce-side join when both datasets are large.
- Use Map-side join when one dataset is small enough to broadcast to all Mappers.
- Consider Repartition join when data requires special handling or optimized partitioning.
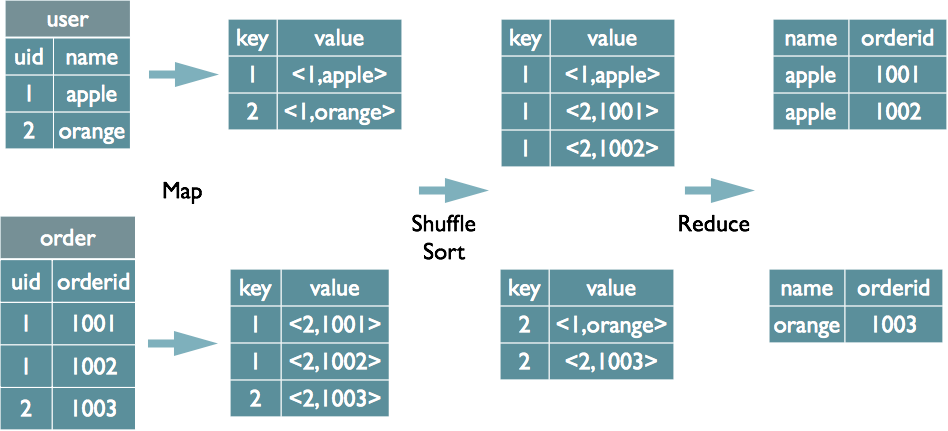
Example — a Reduce-side Join:
select u.name, o.orderid from order o join user u on o.uid = u.uid;
During the Map phase, records from each table are tagged in the output value. In the Reduce phase, the tag is used to determine the data source.
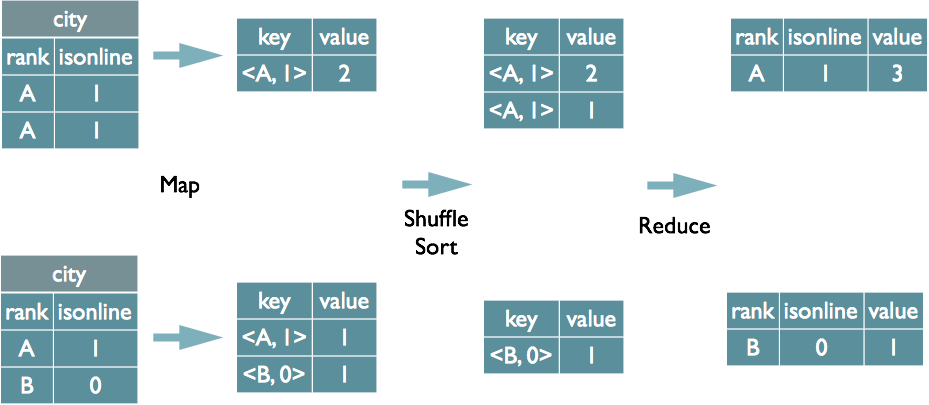
How GROUP BY Is Implemented in MapReduce
Map Phase
- Task: Read input data, process each record, and emit key-value pairs.
- Output: The key is the
GROUP BYfield(s); the value is the data to be aggregated.
Shuffle Phase
- Processing: The framework automatically sorts and groups Mapper output, ensuring that records with the same key are sent to the same Reducer.
Reduce Phase
- Aggregation: The Reducer receives a key and its associated set of values, then performs the aggregation (e.g., count, sum).
- Output: The aggregated result for each group, keyed by the
GROUP BYfield(s).
The GROUP BY fields are combined as the Mapper output key. MapReduce’s built-in sorting ensures that records with the same key arrive together; the Reducer tracks the LastKey to distinguish group boundaries.
The SQL-to-MapReduce Compilation Pipeline
The full compilation process involves six stages:
- Antlr defines SQL grammar rules and performs lexical and syntactic parsing, converting SQL into an Abstract Syntax Tree (AST).
- The AST is traversed to extract the basic building blocks of the query into QueryBlocks.
- QueryBlocks are traversed and translated into an OperatorTree representing the execution plan.
- The logical optimizer transforms the OperatorTree — merging unnecessary
ReduceSinkOperatornodes to reduce shuffle data volume. - The OperatorTree is traversed and translated into MapReduce jobs.
- The physical optimizer transforms the MapReduce jobs and produces the final execution plan.
References:
- https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
- https://blog.csdn.net/weixin_43542605/article/details/122350875